Chapter 2 Overview
Welcome.
In this training you will learn R, RStudio, Git, and GitHub. It’s going to be fun and empowering! You will learn a reproducible workflow that can be used in research and analyses of all kinds, including Ocean Health Index assessments. This is really powerful, cool stuff, and not just for data: I made and published this book using those four tools and workflow.
We will practice learning three main things all at the same time: coding with best practices (R/RStudio), collaborative version control (Git/GitHub), and communication/publishing (RMarkdown/GitHub). This training will teach these all together to reinforce skills and best practices, and get you comfortable with a workflow that you can use in your own projects.
2.1 What to expect
This is going to be a fun workshop.
The plan is to expose you to a lot of great tools that you can have confidence using in your research. You’ll be working hands-on and doing the same things on your own computer as we do live on up on the screen. We’re going to go through a lot in these two days and it’s less important that you remember it all. More importantly, you’ll have experience with it and confidence that you can do it. The main thing to take away is that there are good ways to approach your analyses; we will teach you to expect that so you can find what you need and use it! A theme throughout is that tools exist and are being developed by real, and extraordinarily nice, people to meet you where you are and help you do what you need to do. If you expect and appreciate that, you will be more efficient in doing your awesome science.
You are all welcome here, please be respectful of one another. You are encouraged to help each other.
Everyone in this workshop is coming from a different place with different experiences and expectations. But everyone will learn something new here, because there is so much innovation in the data science world. Instructors and helpers learn something new every time, from each other and from your questions. If you are already familiar with some of this material, focus on how we teach, and how you might teach it to others. Use these workshop materials not only as a reference in the future but also for talking points so you can communicate the importance of these tools to your communities. A big part of this training is not only for you to learn these skills, but for you to also teach others and increase the value and practice of open data science in science as a whole.
2.2 What you’ll learn
- how to THINK about data
- how to think about data separately from your research questions
- how and why to tidy data and analyze tidy data, rather than making your analyses accommodate messy data
- how there is a lot of decision-making involved with data analysis, and a lot of creativity
- how to increase efficiency in your science
- and increase reproducibility
- and facilitate collaboration with others — especially Future You!
- how open science is a great benefit
- find solutions faster
- broaden the impact of your work
- how to learn with intention and community
- think ahead instead of only to get a single job done now
- the #rstats online community is fantastic. The tools we’re using are developed by real people. Real, nice people. They are building powerful and empowering tools and are welcoming to all skill-levels
2.2.1 Tidy data workflow
We will be learning about tidy data. And how to use a tidyverse suite of tools to work with tidy data.
Hadley Wickham and his team have developed a ton of the tools we’ll use today. Here’s an overview of techniques to be covered in Hadley Wickham and Garrett Grolemund of RStudio’s book R for Data Science:
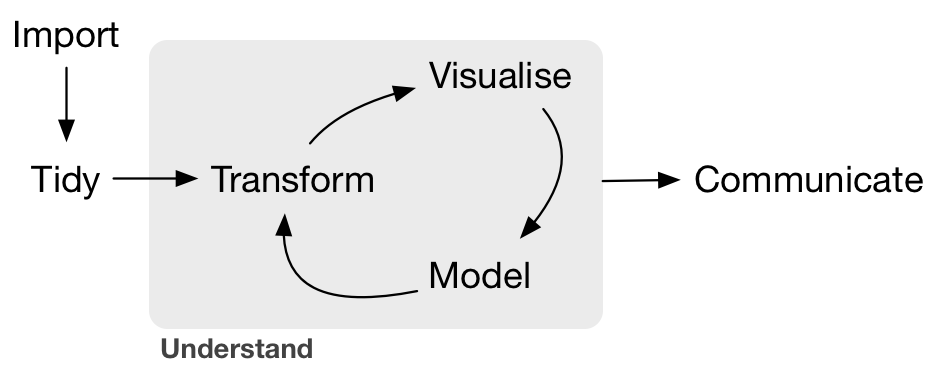
We will be focusing on:
- Tidy:
tidyrto organize rows of data into unique values - Transform:
dplyrto manipulate/wrangle data based on subsetting by rows or columns, sorting and joining - Visualize:
ggplot2static plots, using grammar of graphics principles
- Communicate
- dynamic documents with R Markdown
This is really critical. Instead of building your analyses around whatever (likely weird) format your data are in, take deliberate steps to make your data tidy. When your data are tidy, you can use a growing assortment of powerful analytical and visualization tools instead of inventing home-grown ways to accommodate your data. This will save you time since you aren’t reinventing the wheel, and will make your work more clear and understandable to your collaborators (most importantly, Future You).
2.3 Learning with data that are not your own
One of the most important things you will learn is how to think about data separately from your own research context. Said in another way, you’ll learn to distinguish your data questions from your research questions. Here, we are focusing on data questions, and we will use data that is not specific to your research.
We will be using several different data sets throughout this training, and will help you see the patterns and parallels to your own data, which will ultimately help you in your research.
2.4 Emphasizing collaboration
Collaborating efficiently has historically been really hard to do. It’s only been the last 20 years or so that we’ve moved beyond mailing things with the postal service. Being able to email and get feedback on files through track changes was a huge step forward, but it comes with a lot of bookkeeping and reproduciblity issues (did I do my analyses with thesis_final_final.xls or thesis_final_usethisone.xls?). But now, open tools make it much easier to collaborate.
Working with collaborators in mind is critical for reproducibility. And, your most important collaborator is Future You. This training will introduce best practices using open tools, so that collaboration will become second nature to you!
2.5 By the end of the course…
By the end of the course, you’ll wrangle a few different data sets, and make your own graphics that you’ll publish on webpages you’ve built collaboratively with GitHub and RMarkdown. Woop!
Here are some important things to keep in mind as you learn (these are joke book covers):

2.6 Prerequisites
Before the training, please make sure you have done the following:
- Download and install up-to-date versions of:
- R: https://cloud.r-project.org
- RStudio: http://www.rstudio.com/download
- Git: https://git-scm.com/downloads Note: open the download and follow normal install procedures on your computer but you won’t see any software installed when you’re done
- Create a GitHub account: https://github.com Note! Shorter names that kind of identify you are better, and use your work email!
- Get comfortable: if you’re not in a physical workshop, be set up with two screens if possible. You will be following along in RStudio on your own computer while also watching a virtual training or following this tutorial on your own.
2.7 Credit
This material builds from a lot of fantastic materials developed by others in the open data science community. In particular, it pulls from the following resources, which are highly recommended for further learning and as resources later on. Specific lessons will also cite more resources.
- R for Data Science by Hadley Wickham and Garrett Grolemund
- STAT 545 by Jenny Bryan
- Happy Git with R by Jenny Bryan
- Software Carpentry by the Carpentries